Why did my FCI Failover?
Introduction
In this lab, you will try to find the root cause of an unexpected FCI failover. The goal is to try and identify the cause of an unexpected FCI failover and fix the issue.
Objectives
At the end of this lab, you will be able to:
- Understand the cause of unexpected FCI failover and
- Fix the issue.
Estimated Time
45 minutes
Logon Information
Use the following credentials to login into virtual environment
- Username: corpnet\cluadmin
- Password: Pa$$w0rd
Before starting the training module, we recommend that you launch the labs and give them some time to stabilize. Please be aware that sometimes the AG may be in a resolving state and AG Replicas may be in a disconnected state. This is a platform issue and should stabilize after a few minutes
Environment review
Before you begin with the first exercise in the lab, let's review the lab environment.
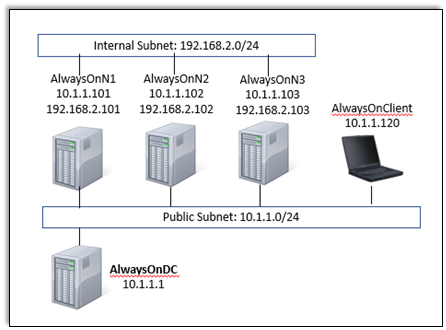
In the lab, you have one Domain Controller and 3 nodes + 1 client computer.
AlwaysOnN1 and AlwaysOnN2 nodes are in the primary Datacenter.
AlwaysOnN3 is in the secondary datacenter.
For this lab, both the datacenters are in the same subnet.
Each node has Windows Server 2022 O/S installed.
SQL Server 2022 failover clustered named instance (SQLFCI\INST1) is installed on AlwaysOnN1 and AlwaysOnN2 nodes.
Exercise 1: Identify why SQL FCI failed over and fix the issue
In this exercise, you will learn why SQL FCI failed over and fix the issue.
Tasks
Log on AlwaysOnClient VM and open Failover Cluster Manager.
Note down the cluster node where SQL Server (INST1) is currently running on (Let's say as an example it is running on AlwaysOnN2 node).
To simulate the unexpected failover, log on AlwaysOnN1 VM. This log on event will run a script that will simulate the unexpected failover. Now you will find that the SQL Server (INST1) is running on the other cluster node. (If it was running on AlwaysOnN2 node in step 2, it should now failover to AlwaysOnN1 node).
Find the root cause of the failover (without opening the script on AlwaysOnN1) using the guidelines and cheat sheet provided below.
What can you do to prevent this unexpected failover in the future?
Find the root cause using the guidelines and cheat sheet provided below.
Guidelines
This is a non-guided activity and the attendees are expected to try and troubleshoot the issue on their own.
You can use any resources (including the internet or your own scripts), to troubleshoot the issue.
You can use the tools discussed in the first module to help troubleshoot the issue.
The possible causes discussed earlier in the lesson can be used as guidance for troubleshooting.
The instructor will discuss the troubleshooting steps, cause and solution in detail after this lab session.
You might have to login directly on the individual nodes to troubleshoot the issue.
Ask yourself the below questions:
- Where do you start?
- What logs will provide me additional insights?
- What tools can I use to troubleshoot this issue?
- Could one or more of the possible causes discussed earlier be the issue here?
Cheat Sheet
Here are some tools that you use to troubleshoot the issue.
- Failover Cluster Manager
- SQL Server Management Studio
- Windows Event Viewer
Below are some logs that you may want to analyze
- Windows Application and System Log
- Windows Cluster Log
- SQL Server Error Logs
- SQL Server Cluster Diagnostics log (stored in the same folder as the SQL Server Errorlogs) – (Node Name)_(Instance Name)_DIAG*.xel
To generate and collect the cluster logs of all nodes in the cluster:
Run PowerShell as administrator and run the below commands
PowerShellImport-Module FailoverClusters Get-ClusterLogDefault command Get-ClusterLog generates cluster.log file on ALL nodes in C:\Windows\Cluster\Reports folder.
All messages are logged using UTC/GMT time. Sometimes it's difficult to translate UTC time to local time, especially for time-zones which has daylight saving. Luckily, cluster log can be generated in local time using parameter UseLocalTime . Here is the sample code.
PowerShellGet-ClusterLog –UseLocalTimeAnother useful parameter is to copy the files to specific location. This command would generate logs and also dump on specified location. in below example, I am dumping logs from all nodes to C:\Temp folder.
PowerShellGet-ClusterLog –Destination "C:\Temp"
Congratulations!
You have successfully completed this exercise. Click Next to advance to the next lab.